Manage your GPU cluster using CoDDL
The CoDDL system is a resource management framework for deep learning training jobs over GPU clusters. It automatically manages the training of multiple AI models to run fast and efficiently in a GPU cluster. When a developer submits a model for training, the system automatically accelerates the training by parallelizing its execution with multiple GPUs to utilize them simultaneously.

Efficient training via elastic resource sharing
The CoDDL system is especially designed for elastic resource sharing that enables the job scheduler to optimize the cluster-wide performance by elastically re-adjusting the GPU shares across multiple training jobs, even when some of the jobs are already running. CoDDL is designed to minimize the system overhead of GPU share re-adjustment for precise and efficient resource allocation decisions that substantially increase the overall cluster performance.
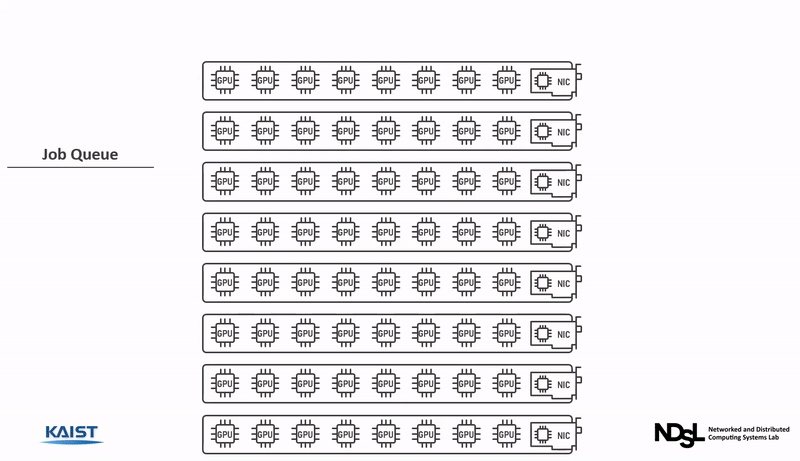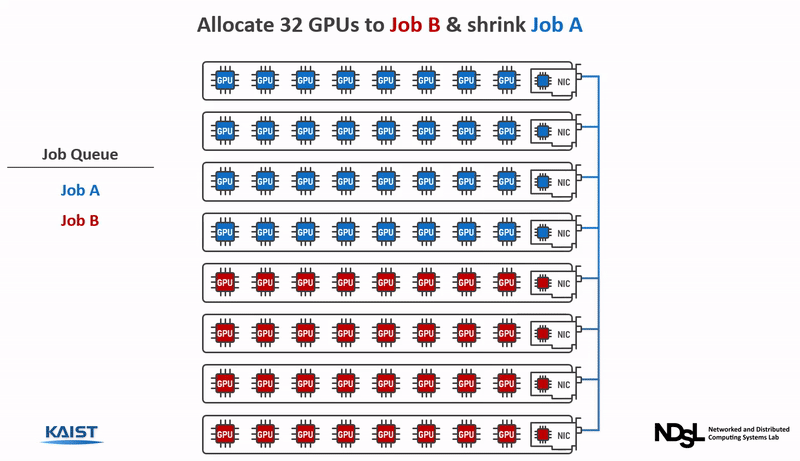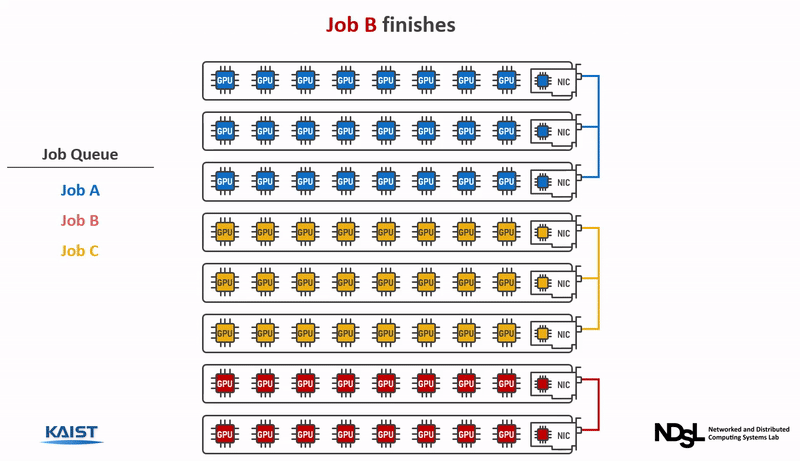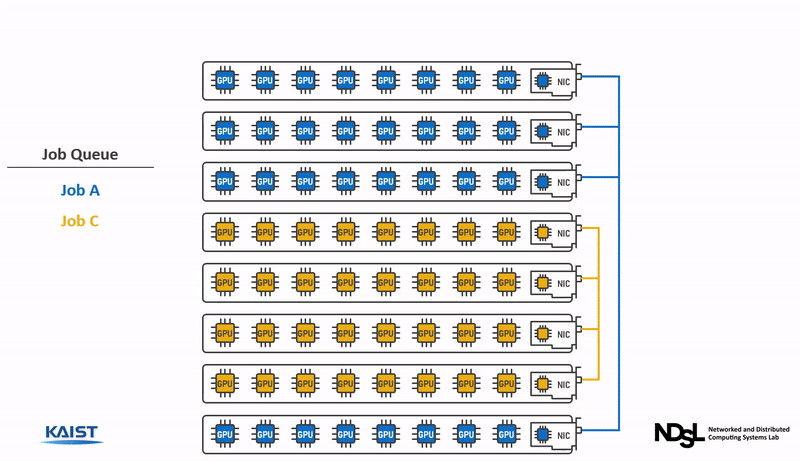
Benefits
The CoDDL system is beneficial for both model developers and cluster operators. Model developers can save their effort for writing distributed training code as it is automatically done by the CoDDL back-end system. They also do not need to determine how many GPUs to request or how to distribute their assigned GPUs across their multiple training jobs — they can simply request throughput objectives (e.g., deadline) of each job to the system, then the system will automatically assign GPUs to achieve objectives. Meanwhile, cluster operators can serve the training jobs efficiently thanks to the highly optimized elastic job scheduling system implemented by the CoDDL system.
